Prompt Caching
Fecha de creación del post: 3 de septiembre de 2025
Autor: Abraham García
Introducción
Prompt caching es una técnica que permite reutilizar partes estáticas y repetitivas de un prompt para mejorar la latencia e incluso reducir el costo por tokens al momento de enviar una entrada a OpenAI.
En muchos casos, los prompts incluyen contenido repetitivo como instrucciones, ejemplos y definiciones de comportamiento, los cuales consumen tokens innecesariamente.
El sistema de OpenAI detecta este patrón y aprovecha solicitudes previas para almacenar en caché dichos fragmentos, optimizando así las peticiones posteriores.
Estructura de los prompts
El caching se activa cuando el inicio del prompt es exactamente igual en cada solicitud.
Esto significa que todo el contenido estático (instrucciones, ejemplos, contexto fijo) debe colocarse al principio del prompt, y la parte dinámica (entrada del usuario) debe ir al final.
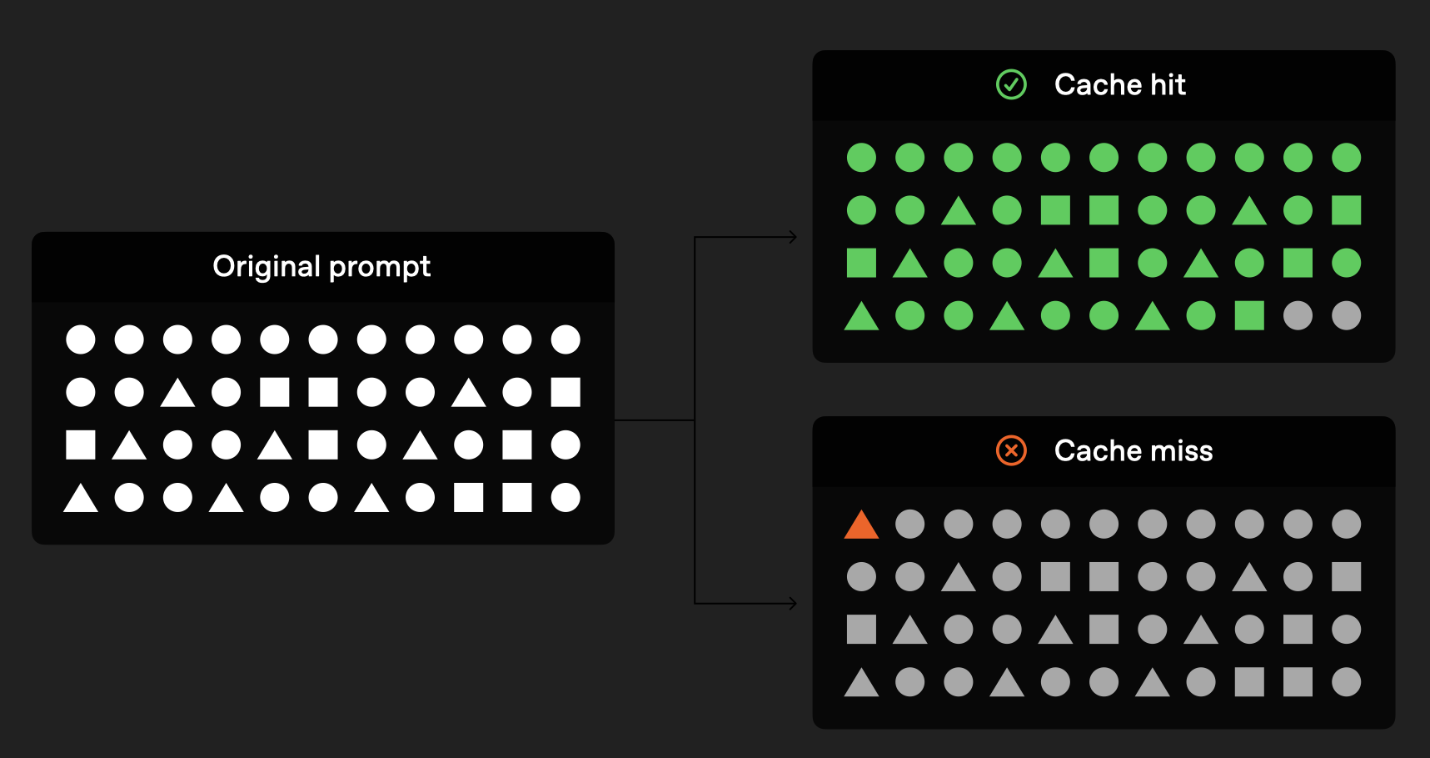
De esta forma, el sistema puede identificar qué fragmentos se repiten y aplicar caching de manera más efectiva.
¿Cómo funciona?
- El caching se activa automáticamente en prompts más largos de 1024 tokens.
- Cada petición incluye un hash del inicio del prompt (generalmente los primeros 256 tokens, aunque puede variar entre modelos).
- Si el hash coincide con prompts previamente procesados, el sistema reutiliza los cálculos ya realizados.
- Es recomendable utilizar el parámetro
prompt_cache_keyen peticiones que comparten instrucciones, lo cual facilita al sistema identificar y aplicar la caché de forma más consistente.