Modelos OpenAI
Fecha de creación del post: 3 de septiembre de 2025
Autor: Abraham García
¿Qué modelo elegir?
Al momento de trabajar con los modelos de OpenAI es común preguntarse cuál es el más adecuado para cada situación. Existen dos grandes categorías:
- Reasoning Models (modelos de razonamiento): diseñados para tareas que requieren múltiples pasos lógicos, análisis profundo o resolución de problemas complejos.
- GPT Models (modelos GPT): enfocados en generación de texto versátil, conversación fluida y aplicaciones generales de lenguaje natural.
Es importante destacar que no existe un modelo universalmente mejor que otro. La elección depende del contexto y las necesidades específicas de la aplicación. Algunos modelos son más adecuados para razonamiento complejo, mientras que otros se ajustan mejor a interacciones rápidas, generación creativa de texto o soporte conversacional.
Reasoning Models
Los modelos de razonamiento fueron entrenados con técnicas avanzadas de aprendizaje para pensar antes de responder. A diferencia de los modelos generales, estos están optimizados para invertir más pasos internos en el análisis, lo que los hace ideales para:
- Resolver problemas complejos.
- Trabajar con código y depuración.
- Manejar flujos costosos donde se requiere alta precisión.
Estos modelos, conocidos como o-series, fueron diseñados específicamente para tareas exigentes, dedicando más tiempo de procesamiento antes de dar una respuesta final.
Ejemplo de uso
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
Write a bash script that takes a matrix represented as a string with
format '[1,2],[3,4],[5,6]' and prints the transpose in the same format.
`;
const response = await openai.responses.create({
model: "gpt-5",
reasoning: { effort: "medium" },
input: [
{
role: "user",
content: prompt,
},
],
});
console.log(response.output_text);
Puntos clave
En este ejemplo, lo más importante es la propiedad reasoning.effort, que define qué tanto razonamiento debe aplicar el modelo antes de responder. Este valor está directamente relacionado con la cantidad de tokens que el modelo consume en el proceso de razonamiento previo a la respuesta.
low → Respuestas más rápidas y económicas en términos de tokens, aunque con menor profundidad.
medium → Valor predeterminado, ofrece un balance entre costo y calidad.
high → Mayor esfuerzo de razonamiento, útil en problemas muy complejos, aunque más costoso en tokens.
Control de costos
Para gestionar manualmente el gasto de tokens en las respuestas, se puede utilizar la propiedad:
max_output_tokens
GTP models
Los modelos GPT se caracterizan por su costo-eficiencia y por estar diseñados para ofrecer respuestas rápidas. Su arquitectura y entrenamiento están optimizados para tareas generales de lenguaje natural, lo que los convierte en una opción práctica cuando se requiere:
- Velocidad de respuesta: ideales para aplicaciones en tiempo real o interacción con usuarios finales.
- Bajo costo: permiten ejecutar muchas consultas con un gasto menor de tokens en comparación con modelos de razonamiento.
- Versatilidad: pueden adaptarse a tareas de redacción, generación de texto creativo, asistencia en conversaciones, resúmenes y más.
El objetivo principal de estos modelos es ejecutar tareas específicas a gran velocidad y bajo costo, manteniendo un buen equilibrio entre calidad de salida y eficiencia operativa.
En resumen, los GPT Models son la mejor opción cuando se busca rapidez, economía y respuestas confiables para tareas comunes, sin la necesidad de procesos de razonamiento prolongado.
Comparativa entre GPT Models y o-series (Reasoning Models)
La elección entre GPT models y o-series models depende del tipo de tarea que se desee resolver. A continuación, se presenta una comparativa estructurada:
Speed and Cost
- GPT Models → Son más rápidos y tienden a costar menos, ya que su razonamiento es directo y no requiere múltiples pasos internos.
- o-series Models → Invierten más tokens en el proceso de razonamiento, lo que puede incrementar el costo y la latencia.
Well-defined Tasks
- GPT Models → Manejan con eficiencia tareas explícitamente definidas, como redacción, resúmenes, clasificación de texto o respuestas conversacionales rápidas.
- o-series Models → No están limitados a tareas simples, pero su ventaja surge en escenarios donde la definición de la tarea no es tan clara.
Accuracy and Reliability
- GPT Models → Ofrecen resultados consistentes en tareas generales, pero pueden tener menor precisión cuando el problema requiere razonamiento profundo.
- o-series Models → Funcionan como tomadores de decisiones más confiables, ya que procesan pasos adicionales para llegar a una respuesta fundamentada.
Complex Problem-solving
- GPT Models → Se limitan a entregar respuestas rápidas y directas, sin profundizar en ambigüedades complejas.
- o-series Models → Están diseñados para resolver problemas complejos, trabajar con ambigüedad y analizar situaciones con múltiples variables antes de dar una solución.
Conclusión
- Usa GPT Models si tu prioridad es velocidad, costo-eficiencia y tareas bien definidas.
- Elige o-series Models cuando necesites precisión, fiabilidad y resolución de problemas complejos.
De esta forma, no hay un modelo universalmente mejor: la decisión depende del caso de uso específico.
¿Cómo seleccionar un modelo?
La elección del modelo depende completamente de la aplicación específica que se le quiera dar. No existe un modelo universalmente mejor que otro: cada uno ofrece ventajas diferentes que se ajustan mejor a ciertos escenarios.
En el caso de esta investigación, se busca un análisis comparativo que permita entender las diferencias clave entre los modelos de OpenAI.
Herramienta oficial de comparación
Una forma muy eficiente de seleccionar un modelo es utilizar la herramienta oficial que ofrece OpenAI para comparar sus modelos.
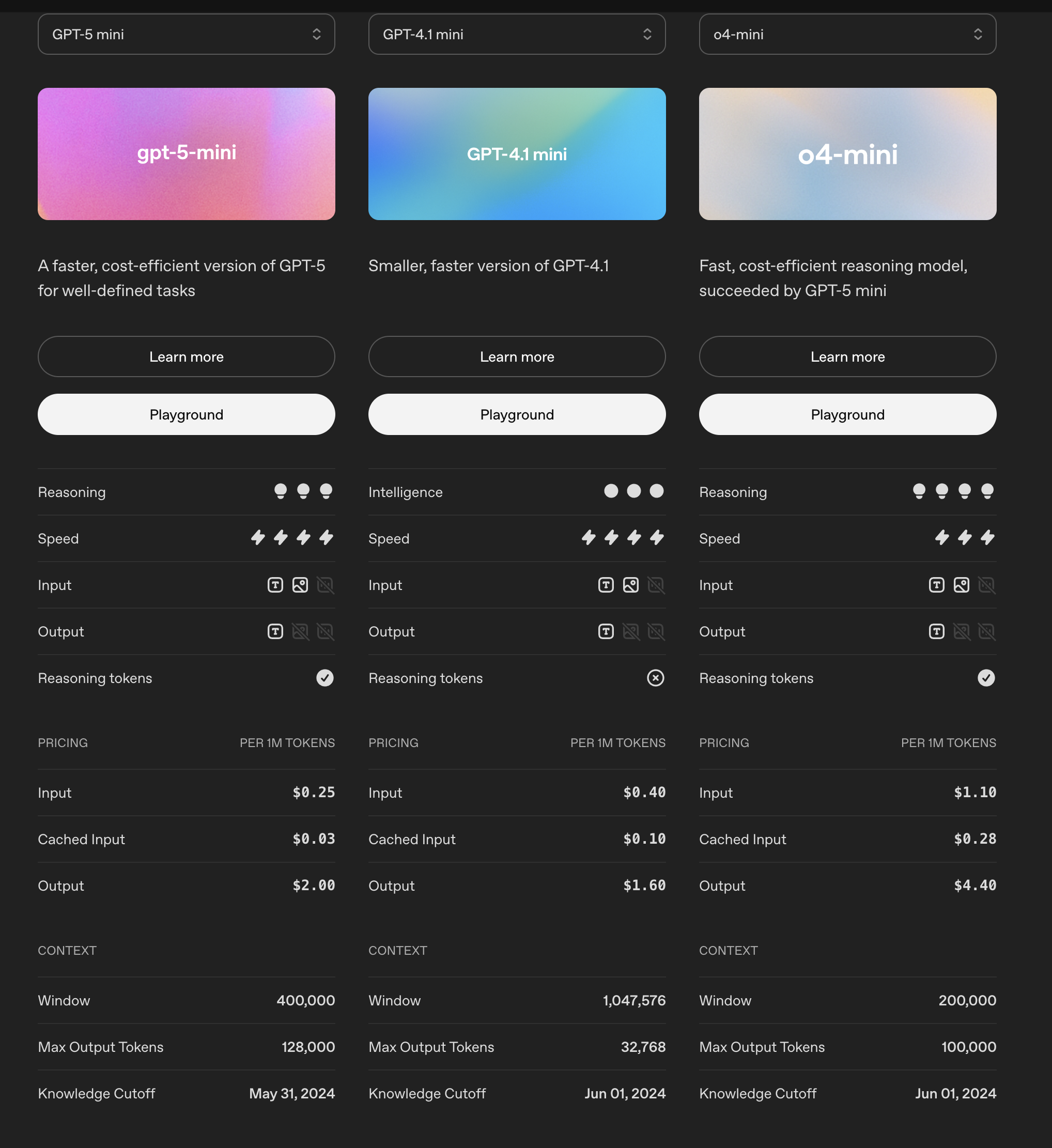
Esta tabla presenta métricas esenciales para analizar al momento de elegir un modelo. Los aspectos más importantes a destacar son los siguientes:
Factores clave en la elección
-
Reasoning
Es el proceso interno que el modelo utiliza para construir y generar una respuesta a partir de la entrada proporcionada.Nota: Este proceso no es visible para el usuario, pero sí consume tokens, lo cual afecta tanto al costo como al tiempo de respuesta.
-
Speed
Representa el tiempo de procesamiento: cuánto tarda el modelo en recibir la entrada y devolver la salida.- Modelos GPT → más rápidos.
- Modelos de razonamiento → más lentos, porque invierten más pasos en analizar.
-
Context Window
Indica la cantidad máxima de tokens que el modelo puede mantener en memoria para generar una respuesta coherente.- Cuanto mayor sea la ventana de contexto, mejor será el modelo para manejar documentos largos o conversaciones extensas.
-
Pricing
Define el costo por millón de tokens, dividido generalmente en:- Entrada (input tokens)
- Cache (contexto reutilizado o almacenado temporalmente)
- Salida (output tokens)
-
Intelligence
Se refiere a la capacidad del modelo de comprender, abstraer y razonar sobre entradas complejas, con el fin de entregar una respuesta coherente y alineada al problema planteado.
Conclusión
Seleccionar un modelo implica balancear factores como velocidad, costo, contexto disponible, capacidad de razonamiento y nivel de inteligencia requerido.
- Para tareas rápidas y económicas, los GPT models son la mejor opción.
- Para problemas complejos que requieren razonamiento profundo y fiabilidad, los o-series models resultan más adecuados.
La herramienta oficial de comparación permite evaluar estas dimensiones de manera práctica y tomar una decisión informada.