Ejemplo Resumen Noticias RSS
Proyecto: Resumidor RSS → Ollama → Mongo → Webhook
Objetivo: cada vez que haya una nueva entrada en un RSS (o usando un cron que chequee cada X minutos) el flujo genera un resumen con Ollama y lo guarda en Mongo; además ofrece un webhook para consultar los resúmenes.
Topología (lo que ya tienes)
- n8n en Docker (puede comunicarse con
ollamaviahttp://ollama:11434dentro de la red Docker). - ollama con modelo (
llama3.2:1b) descargado o el de tu preferencia. - mongo para guardar.
Flujo n8n (resumen conceptual de nodos)
- Trigger:
Cron(ej. cada 30 minutos) oRSS Feed(si quieres usar nodo RSS). - HTTP Request: si el RSS node da sólo items, no hace falta; pero si quieres obtener el contenido completo del artículo, haz GET a
linkde la entrada. - Set / Function: preparar prompt para Ollama (ej. título + texto + contexto).
- Ollama (n8n node): enviar prompt y recibir resumen.
- Function / Set: crear objeto
{ title, link, summary, source, publishedAt }. - MongoDB node: Insert document (colección
rss_summaries) — usa la conexión que ya configuraste. - Optional: Webhook node: exponer un endpoint
GET /summariesque consulta Mongo y devuelve los últimos N resúmenes.
Configuración práctica de nodos (valores concretos)
1) Trigger: Cron
- Nodo: Cron
- Configuración:
Every 30 minutes(o usaEvery 15 minutessi quieres pruebas rápidas).
2) HTTP Request para contenido completo
- Nodo: HTTP Request
- Método: GET
- URL:
{{$json["link"]}}(si usaste el RSS trigger y quieres el HTML del artículo) - Response Format:
String
Nota: si el HTML es pesado, puedes extraer texto con librería externa, o usar sólo el resumen que trae el feed.
Ejemplo de RSS: El pais
3) XML a JSON
- Nodo: XML to JSON
- Configuración:
Auto detect.
4) Edit Set Fields
- Nodo: Edit Set Fields
- Tomamos
{{ $json.rss.channel.item }}y lo convertimos en un array de objetos array items.
5) Code
- Nodo: Code
- Código:
// Obtenemos el array de items del primer input
const feedItems = $input.first().json.items;
// Creamos un nuevo array mapeado y limpio
const cleanedItems = feedItems.map(entry => {
const rawHtml = entry["content:encoded"] || entry.description || "";
const textOnly = rawHtml
.replace(/<[^>]*>/g, ' ') // Quita HTML
.replace(/\s+/g, ' ') // Colapsa espacios
.replace(/ /gi, ' ') // Decodifica
.replace(/&/gi, '&') // Decodifica &
.replace(/"/gi, '"') // Decodifica "
.replace(/'/gi, "'") // Decodifica '
.trim();
return {
json: {
title: entry.title,
link: entry.link,
description: textOnly
}
};
});
// Devolvemos solo los primeros 2
return cleanedItems.slice(0, 2);
para quedarnos con
[
{
"link":
"https://elpais.com/mexico/2025-08-21/el-proyecto-portero-la-iniciativa-de-la-dea-contra-las-redes-de-contrabando-nuevo-conflicto-entre-mexico-y-la-agencia-antidrogas.html",
"description":
"El lunes 18 de agosto, la DEA, la agencia antidrogas de Estados Unidos, anunció con un comunicado el Proyecto Portero, una iniciativa que busca fortalecer la colaboración con sus socios mexicanos en “la lucha contra los cárteles” para cortar las redes de contrabando que inundan con “mortales drogas sintéticas” a las comunidades estadounidenses. Al día siguiente, la presidenta mexicana, Claudia Sheinbaum, negó que hubiera algún trato con ellos . “Emiten el comunicado, no sabemos con base en qué; nosotros no hemos llegado a ningún acuerdo”, enfatizó en su conferencia de prensa diaria. Seguir leyendo"
}
]
6) AI Agent
- nodo: AI Agent
- Source for prompt: Define below
- Prompt:
Eres un analista de noticias con tono profesional, imparcial y directo.
Tu tarea: resumir y clasificar cada noticia con el máximo realismo, sin suavizar hechos aunque sean explícitos o violentos.
Para CADA noticia recibida (con campos: title, link, description):
Titulo: {{ $json.title }}
link: {{ $json.link }}
description: {{ $json.description }}
1. **Resumen**:
- Sintetiza en 2 a 4 frases los hechos clave.
- No opines, no suavices, no omitas detalles importantes aunque sean duros.
- Si el texto contiene HTML, elimínalo antes de procesar.
2. **Categoría**:
- Asigna una de estas etiquetas, o crea una nueva si no encaja:
* Política / Gobierno
* Narcotráfico / Crimen Organizado
* Conflictos Internacionales / Guerra
* Economía / Negocios
* Sociedad / Justicia
* Desastres / Accidentes
* Cultura / Deporte
- Sé preciso y consistente. Ejemplo: si hay violencia, clasifica en la categoría relacionada aunque la violencia sea secundaria.
3. **Formato de salida texto plano**
4. No uses adjetivos emocionales ni calificativos políticos.
5. Incluye el link tal cual se recibió para trazabilidad.
7) Nodo Ollama (usar el nodo oficial en n8n)
- Nodo: Ollama (o "Ollama Chat Model" según tu versión de n8n)
- Credentials / Base URL:
http://ollama:11434(si n8n está en Docker junto a ollama) — IMPORTANTE: si pruebas desde tu PC fuera de Docker usahttp://localhost:11434. - Model:
llama3.2:1b(ogemma3:1bsi lo tienes). - Input:
{{$json["prompt"]}}(o usamessagessi el nodo admite chat messages:[{"role":"user","content": "..." }]) - Temperature:
0.0 - 0.2(para respuestas más deterministas)
Resultado esperado: una cadena con el resumen o un JSON al que puedes
JSON.parse.
8) Mongo history
- Nodo: MongoDB
- Agrega la cuenta, si usas docker en database es
n8n_memory_chat|root|ejemplo123| host (nombre del container):mongo - Si no tienes
n8n_memory_chatcrea la colección manualmente en mongo
IA Agent
Dependiendo el modelo y la maquina el proceso puede ser mas rapido o mas lento.
En el ejemplo se uso gemma2:2b y solo se limito a dos noticias para que el proceso sea mas rapido. Tardo 42.902s y 1432 Tokens.
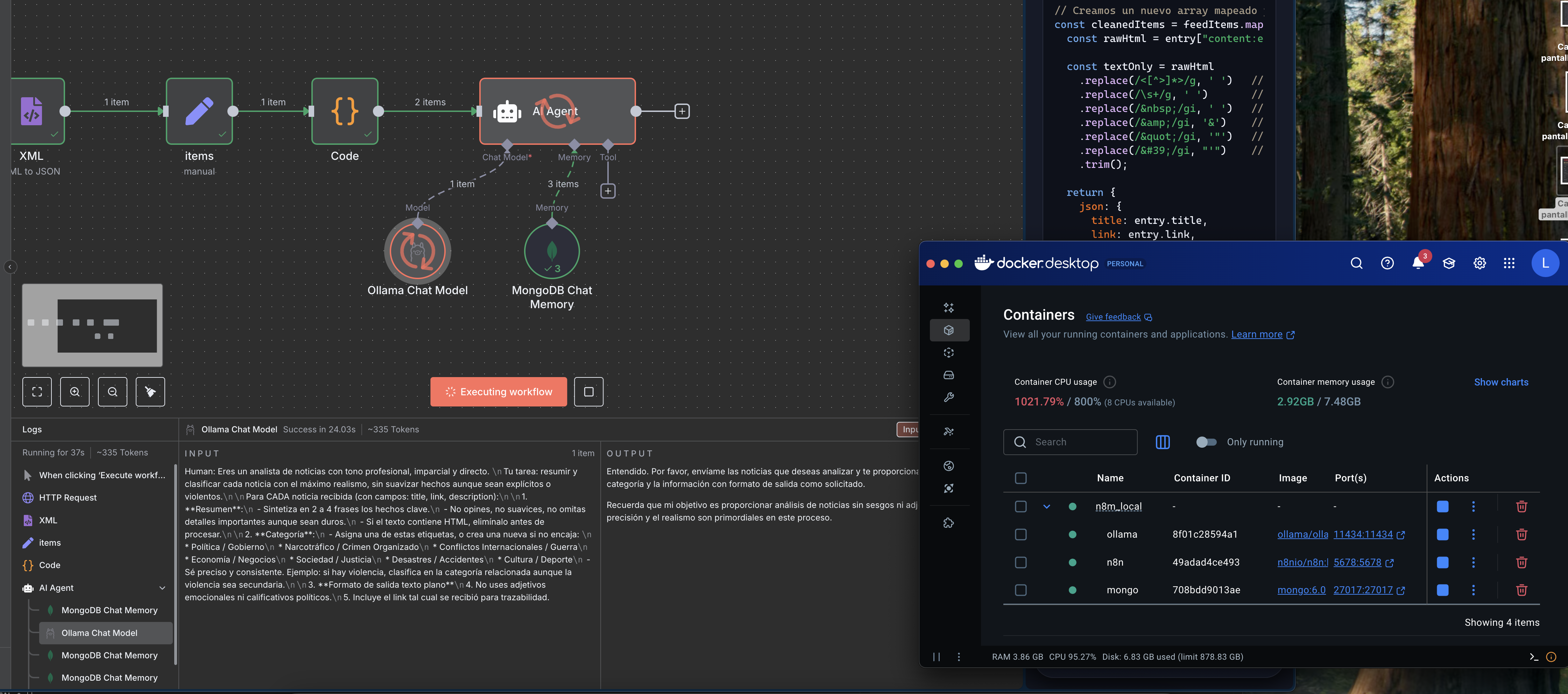
9) Code
Por ultimo se usa un nodo code para limpiar el texto.
- Nodo: Code
- Código:
// Obtenemos todos los elementos de entrada
const items = $input.all();
return items.map(item => {
const rawOutput = item.json.output || "";
// Limpiador de Markdown y espacios
const cleanText = rawOutput
// Quita encabezados tipo ## o #
.replace(/^#+\s*/gm, '')
// Quita viñetas tipo *, -, + al inicio de línea
.replace(/^[\*\-\+]\s*/gm, '')
// Quita asteriscos de negritas o itálicas
.replace(/\*\*/g, '')
.replace(/\*/g, '')
// Quita guiones de listas si quedan
.replace(/^\s*-\s*/gm, '')
// Reemplaza múltiples saltos de línea por uno solo
.replace(/\n{2,}/g, '\n')
// Colapsa espacios múltiples
.replace(/[ \t]+/g, ' ')
.trim();
return {
json: {
output: cleanText
}
};
});
Archivo
Guardalo como Analista RSS.json en la carpeta workflows de n8n. Descargar archivo