SpeechRecognition y SpeechSynthesisUtterance
SpeechRecognition es una interfaz de Web Speech API, que es el controlador para el servicio de reconocimiento. Esta API permite solicitar el microfono del dispositivo para grabar la voz del usuario. Una vez que el usuario comience a hablar se almacena esta información en el navegador.
Nota: Este servicio require del uso de internet, esto debido a que la información se manda a un servidor con la finalidad obtener el texto generado por voz.
Una vez que el servicio inicia el navegador comienza a escuchar hasta el momento que el usuario se quede en silencio o exista una larga pausa.
SpeechSynthesisUtterance es una interfaz de Web Speech API. Este servicio permite elegir entre diferentes tipos de voces, en diferentes idiomas para el audio de salida.
Ejemplo práctico
Este ejemplo fue creado para realizar un demo de diken. El proyecto esta pensado para realizar un asistente que apoye a los trabajadores acerca de los productos de la empresa.
Este es el código básico que se debe de colocar en el html. Los dos componentes son los siguientes:
- Botón para comenzar y parar la grabación.
- Elemento de salida de texto.
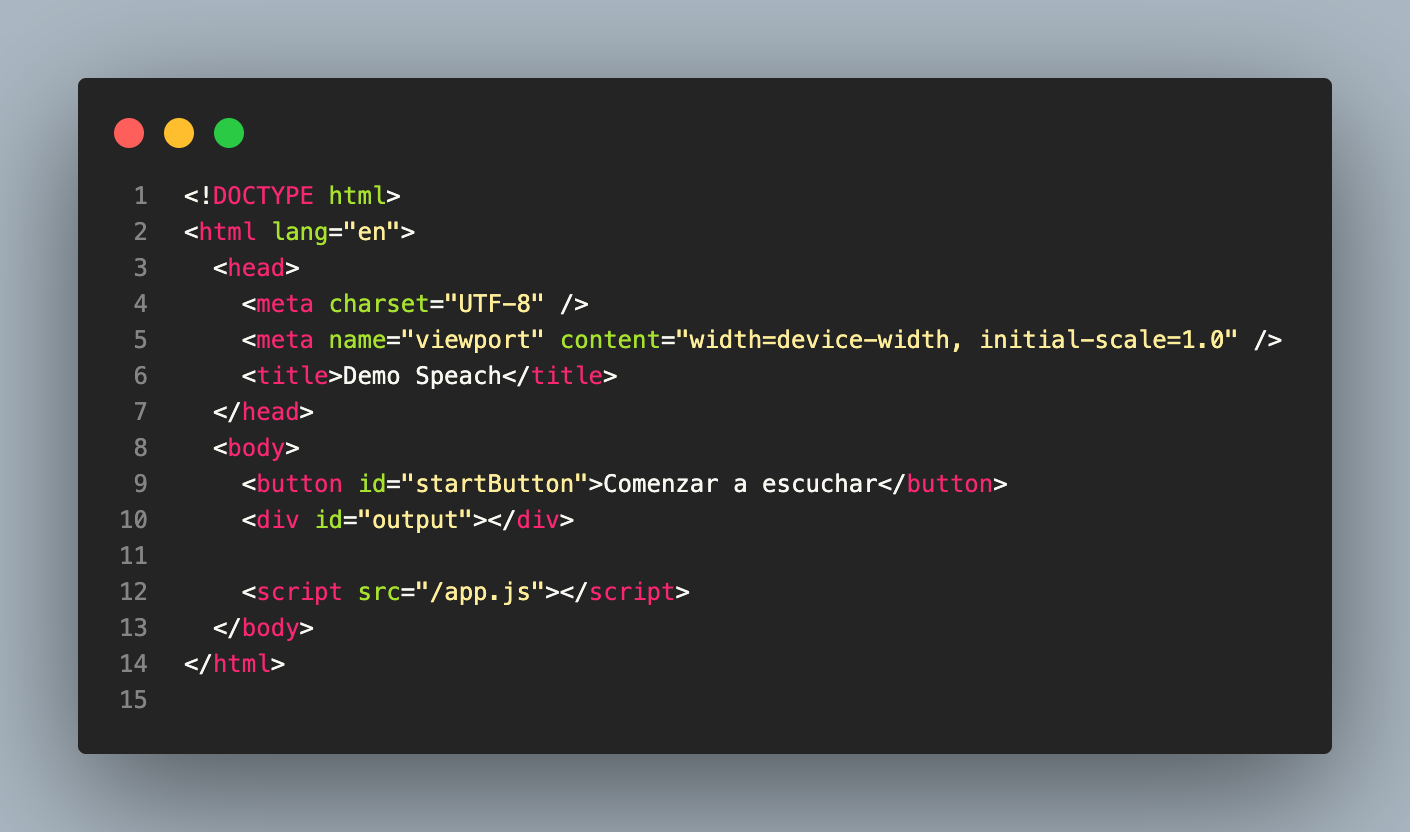
Código javascript

Algo importante a notar en el código es el valor de continuous. La api puede trabajar en dos modos:
- Escuchar hasta que exista una pausa.
- Seguir escuchando hasta que se provoque un evento que detenga a la API.
const startButton = document.getElementById("startButton"); // Obtenemos el botón para rastrear la acción de click
const outputDiv = document.getElementById("output"); // OPCIONAL: Sirve para mostrar el texto obtenido
const recognition = new (window.SpeechRecognition ||
window.webkitSpeechRecognition ||
window.mozSpeechRecognition ||
window.msSpeechRecognition)(); // Se inicializa la libreri apara pasar de voz a códogio
recognition.lang = "es-MX"; // Se configura el idioma objetivo para escuchar.
recognition.continuous = true; // Seguirá escuchando apesar que exista una pausa.
let isActive = false;
let texto = "";
El código anterior configura las varaibles fundamentales para el ejemplo.
Ahora, comenzaremos a escuchar la voz del usuario. Se agrega un evento click a nuestro botón. Con la primer acción se comienza el servicio de reconocimiento de voz, con la segunda acción se detiene.
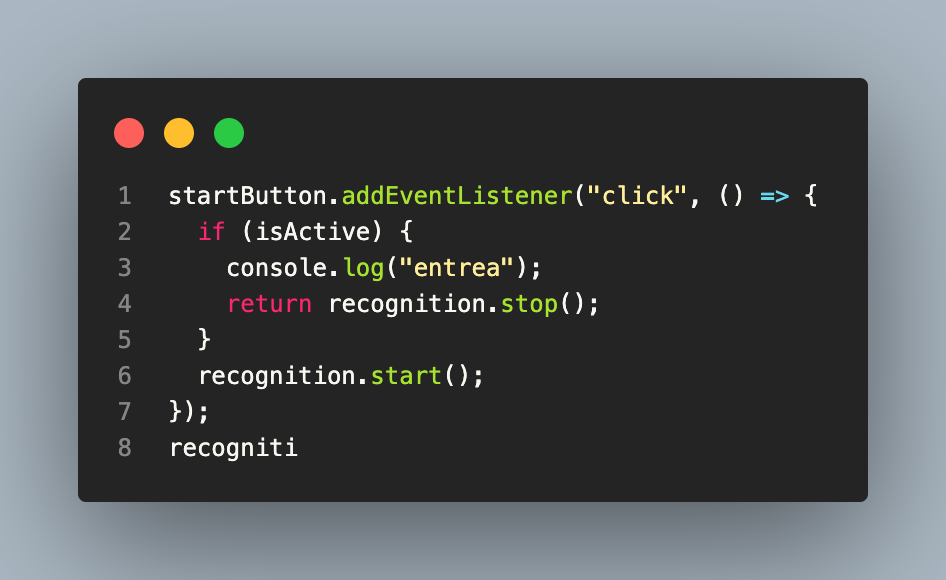
Se definen los eventos necesarios: comenzar, resultados y tener el reconocimeitno de voz.
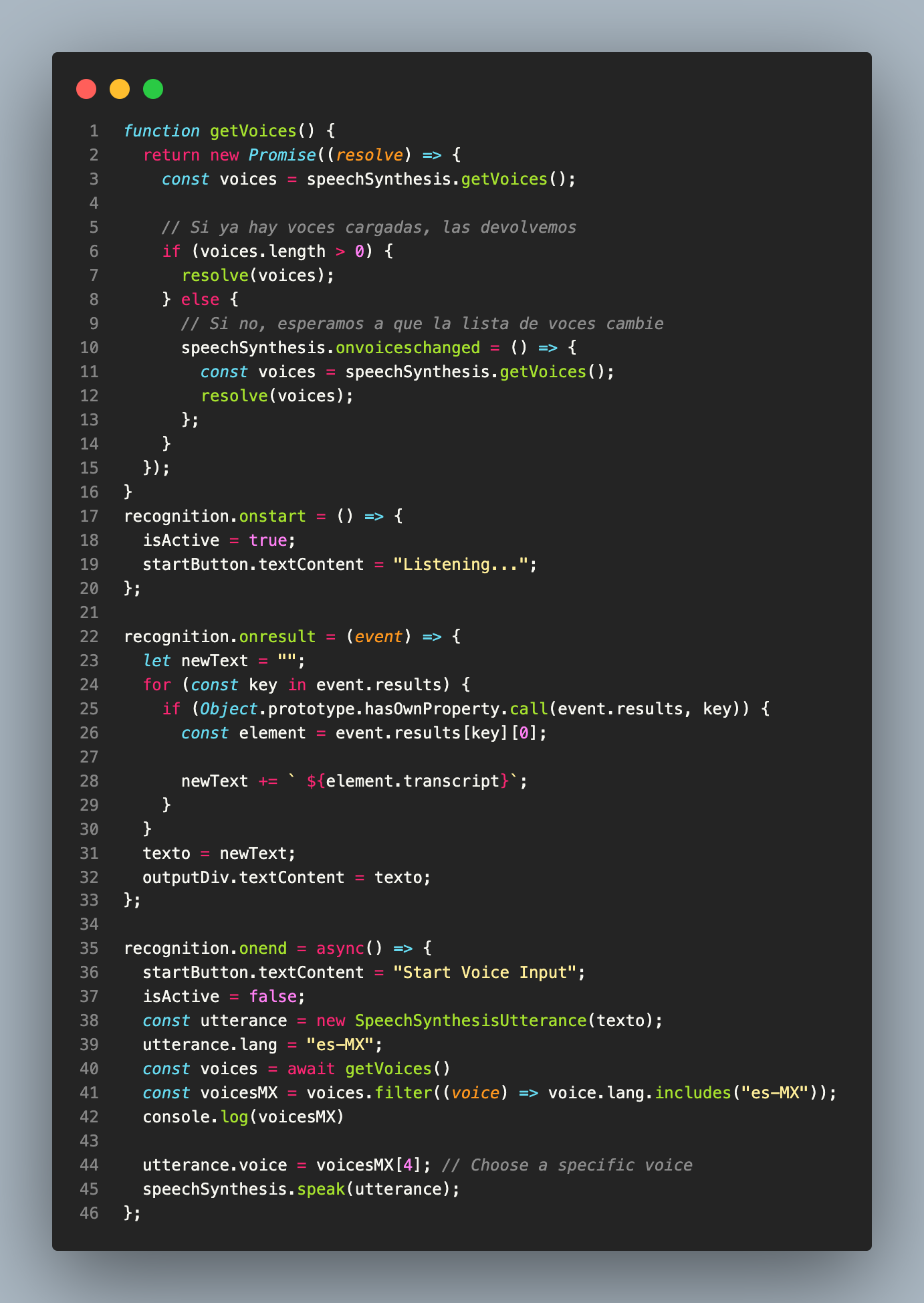
El proceso comienza con el evento onstart ya que le avisa a la UI que se comenzará a grabar.
Cuando existe una pausa o el usuario deja de habar llama al evento onresult. Este evento concatena cada uno de los resutados que vienen en el objeto del evento. En este caso, el texto se almacena y se actualiza en el div creado en index.html.
Cuando el usuario vuelve a dar click al botón se activa el evento onend, en donde se avisa que la API ya no escuchará ni convertirá voz a texto. En este evento se realiza el proceso inverso. Ahora, partiendo del texto obtenido, se toma como valores iniciales para escuchar ese texto en un audio.
const utterance = new SpeechSynthesisUtterance(texto); // Inicializa la api con el texto a reproducir como valor inicial
utterance.lang = "es-MX"; // Se modifica el idioma con el cual se desea escuchar el audio.
const voices = await getVoices() // La api cuenta con diferentes voces en diferentes idomas.
const voicesMX = voices.filter((voice) => voice.lang.includes("es-MX")); // Se obtienen las voces dispoibles para el idioma español-México.
utterance.voice = voicesMX[4]; // Se elige una voz
speechSynthesis.speak(utterance); // La api genera el audio deseado.
Es importante resaltar que no todas las voces estan disponibles en todos los dispositivos, esto depende del navegador y del sistema oprativo del usuario.