Análisis Completo de Tecnologías Lipsync
¿Qué es Lipsync?
El lipsync (sincronización de labios) es una tecnología de inteligencia artificial que permite sincronizar automáticamente los movimientos de los labios de una persona en un video con un audio específico. Esta tecnología utiliza redes neuronales profundas para analizar tanto las características faciales como las características acústicas del audio para generar movimientos labiales realistas.
Aplicaciones principales:
- Doblaje automático: Traducir contenido a diferentes idiomas manteniendo sincronización labial
- Avatares virtuales: Crear personajes digitales que hablen de forma realista
- Corrección de audio: Ajustar videos donde el audio y video no están sincronizados
- Contenido generativo: Crear videos de personas hablando con texto convertido a voz
Benchmarking de Servicios Cloud
- 🎨 Everypixel — labs.everypixel.com/lipsync
- 🎭 HeyGen — heygen.com
- 🤖 D-ID — d-id.com (API robusta)
- 🎯 AKOOL — akool.com/es-es/pricing
- 🎪 Tavus — tavus.io
- 🔧 Gooey.ai — gooey.ai/Lipsync
Estos servicios facilitan el flujo (upload audio + video → lipsync) sin gestionar GPUs locales.
Implementación Local - Repositorios Open Source
Prerrequisitos Técnicos
Instalar conda
https://www.anaconda.com/download/success
# Configuración de entorno con el python requerido
conda create -n lipsync python=3.10
conda activate lipsync
¿Qué son los Checkpoints?
Los checkpoints son archivos que contienen:
- Pesos de la red neuronal: Valores optimizados de todas las conexiones neuronales
- Arquitectura del modelo: Estructura de capas y neuronas
- Estado de entrenamiento: Información sobre el proceso de aprendizaje
Son esenciales porque:
- Evitan re-entrenar modelos (ahorro de tiempo/recursos)
- Permiten usar modelos pre-entrenados con millones de parámetros
- Facilitan la reproducibilidad de resultados
🌊 Wav2Lip - Implementación Local
Repositorio: justinjohn0306/Wav2Lip
Checkpoint utilizado:
- Fuente: Hugging Face - wav2lip.pth
- Tamaño: ~44 MB
- Arquitectura: Discriminador + Generador GAN
Resultados observados:
- Hardware: CPU
- Calidad: Limitada, movimiento de boca poco natural
- Tiempo de procesamiento: Variable según duración de video
Resultados observados usando CPU:

🔄 Diff2Lip - Versión Mejorada
Repositorio: soumik-kanad/diff2lip
Arquitectura técnica:
- Basado en Modelos de Difusión
- Mejora sobre Wav2Lip usando técnicas de denoising
- Mayor calidad teórica pero más demandante computacionalmente
Resultados observados:
- Hardware: CPU
- Calidad: No logro terminar el proceso
- Tiempo de procesamiento: Variable según duración de video, fueron 4 minutos
Resultados observados usando CPU:

Comparativa Hardware: AMD vs NVIDIA
NVIDIA (CUDA)
Ventajas:
- Ecosistema maduro: CUDA ampliamente soportado
- Compatibilidad: Prácticamente todos los frameworks de IA
- Optimización: Libraries específicas (cuDNN, TensorRT)
- Documentación: Extensa y bien mantenida
Configuración típica:
# Verificar instalación CUDA
nvidia-smi
nvcc --version
# Instalación PyTorch con CUDA
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
AMD (ROCm)
Desventajas observadas:
- Compatibilidad limitada: No todos los frameworks soportan ROCm
- Instalación compleja: Requiere configuración específica del sistema
- Recursos: Demanda ~27GB de memoria para instalación completa
- Documentación: Menos extensa que CUDA
Problemas encontrados:
# Error típico en instalación ROCm
sudo apt install rocm-dev rocm-libs
# Error: Insufficient disk space (27GB required)
Conclusión técnica: NVIDIA sigue siendo la opción más viable para desarrollo de IA, especialmente para lipsync que requiere procesamiento intensivo de video.
Análisis de Costos - Servidores GPU
Tabla Comparativa Actualizada
| Proveedor | GPU | VRAM | Precio (USD/h) | Precio (USD/mes)* | Adecuado para Lipsync |
|---|---|---|---|---|---|
| RunPod | RTX A5000 | 24 GB | $0.27 | ~$194 | ✅ Excelente |
| Google Cloud | Tesla T4 | 16 GB | $0.16 | ~$115 | ✅ Bueno |
| Lambda Labs | RTX 6000 | 24 GB | $0.50 | ~$360 | ✅ Premium |
| Salad | RTX 2070 | 8 GB | $0.03 | ~$22 | ⚠️ Limitado |
| Hyperstack | A4000 | 16 GB | $0.15 | ~$108 | ✅ Equilibrado |
| AWS | Tesla T4 | 16 GB | $0.526 | ~$378 | ✅ Costoso |
*Calculado para uso continuo (24/7)
Recomendaciones por Caso de Uso
- Para desarrollo/pruebas: Salad (más económico, limitaciones aceptables)
- Para producción pequeña: Hyperstack o Google Cloud
- Para producción intensiva: RunPod (mejor relación precio/rendimiento)
- Para empresas: AWS/GCP (mayor confiabilidad, soporte)
Implementación Final - Demo con D-ID
Justificación de la Elección
D-ID fue seleccionado por:
- Tiempo de respuesta: Procesamiento más rápido que alternativas
- Calidad aceptable: Balance entre realismo y velocidad
- API robusta: Documentación completa y ejemplos
- Embebible: Posibilidad de integración en aplicaciones web
Demo desplegado: demo-chat-lipsync.netlify.app
Limitaciones del Demo Final
- UI no personalizable: El embed de D-ID no permite modificación de interfaz
- Dependencia externa: Requiere conexión a servicios de D-ID
- Costos variables: Facturación por uso de la API
- Latencia de red: Tiempo adicional por procesamiento en la nube
Conclusiones y Recomendaciones
Conclusiones Técnicas
- Lipsync en tiempo real sigue siendo un desafío técnico significativo, por costos servicios cloud, entre mas usuarios mas costos y mas procesamiento
- Hardware especializado (GPUs con >16GB VRAM) es prácticamente obligatorio
- Servicios cloud ofrecen mejor relación costo-beneficio para la mayoría de casos de uso
- Calidad vs Velocidad requiere compromiso según el caso específico
Informe — Pruebas con Wav2Lip y Diff2Lip
Resumen inicial Probamos modelos como Wav2Lip y Diff2Lip y comprobamos que el procesamiento de video es mucho más exigente que el de tareas de texto o imágenes. Para obtener resultados fluidos y en tiempo razonable hace falta hardware especializado (principalmente GPUs NVIDIA con soporte CUDA). A continuación explico detalles, limitaciones, costos y recomendaciones.
Repositorios y herramientas
- Se probaron repositorios y modelos recomendados (Wav2Lip y Diff2Lip).
- Estas herramientas usan intensamente CUDA y arquitecturas optimizadas para GPU, por eso lo ideal son tarjetas NVIDIA.
Pruebas realizadas y resultados
-
Hicimos pruebas solo con CPU (sin GPU). El procesamiento con CPU funcionó, pero:
- El rendimiento fue muy lento y el consumo de energía mayor.
- La reproducción/visibilidad del video no fue fluida; la calidad final quedó por debajo de lo esperado.
-
Con GPU se espera mejor desempeño, pero nuestras pruebas eran con una sola GPU y hardware inferior al utilizado en proyectos comerciales o en la documentación oficial. Por eso los resultados seguían siendo más pobres que los de implementaciones profesionales.
-
Diferencia de entorno: muchos proyectos están pensados para Linux y para configuraciones con múltiples GPU y mucha memoria (por ejemplo clústeres con varias GPUs y decenas de GB de RAM). Nosotros probamos en Windows y con recursos limitados, lo que impactó negativamente.
Detalles técnicos sobre Diff2Lip (y comportamiento del entrenamiento)
- Diff2Lip toma un fotograma y genera puntos/landmarks que indican la posición de la boca.
- Ese proceso se refina iteración tras iteración: al inicio genera puntos groseros y con más pasadas va limpiándolos hasta formar la boca final.
- Este procedimiento requiere muchas iteraciones y capacidad de cómputo; sin suficiente potencia no alcanza los resultados esperados.
Ejemplo:
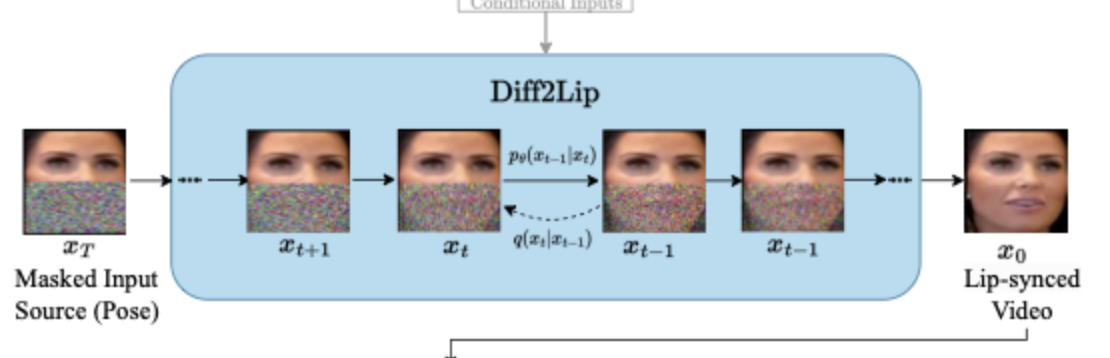
Costos y opciones en la nube
- Al investigar servicios en la nube vimos que la generación de video y el procesamiento intensivo pueden costar mucho. Cifras orientativas: $300–$400 USD/mes para una capacidad limitada; si la base de usuarios crece (será más costoso).
- Con baja adopción (p. ej. ~200 usuarios/pruebas) el costo puede ser más manejable; con adopciones grandes se encarece mucho.
- Existen servicios gratuitos o de bajo costo para modelos menos exigentes (traducción de texto, análisis de lenguaje, clasificación de objetos), pero la generación de video y la transformación de audio siguen siendo las tareas más caras y complejas.
Trade-offs: hardware local vs nube
- Hardware local: ventaja en control y, potencialmente, menor costo a largo plazo si tienes mucha carga; desventaja en mantenimiento (tener servidores siempre encendidos, respaldo de energía, mantenimiento físico y actualizaciones).
- Nube: evita la infraestructura física, pero el servicio y la escala tienen un costo recurrente alto.
- Ambas opciones son caras de distintas maneras: local requiere inversión y operación; nube externaliza la infraestructura pero cobra por uso.
Conclusión La complejidad de combinar varias técnicas de IA para generación/transformación de video (procesamiento de audio + fotogramas + refinamiento iterativo) hace que el proyecto sea costoso en cómputo y en operación. Para lograr resultados comerciales o en tiempo real necesitarías:
- Entrenar y ajustar los modelos específicamente para tu caso (no usar solo pesos preentrenados sin adaptación).
- Hardware adecuado (múltiples GPU y suficiente RAM), o presupuesto para servicios en la nube de alta capacidad.
- Evaluar si ciertas partes del flujo pueden delegarse a servicios más baratos (p. ej. traducción o clasificación) y reservar GPU para la generación estricta de video.