RAG en base de datos creadas
¿Qué es RAG?
RAG son las siglas de Retrieval-Augmented Generation (Generación Aumentada por Recuperación). Es un modelo de inteligencia artificial que mejora la capacidad de un LLM (modelo de lenguaje grande) para generar respuestas precisas y relevantes, basándose en un conjunto de datos externos.
En lugar de depender únicamente de los datos con los que fue entrenado, RAG recupera información de una base de datos o corpus de conocimiento y luego aumenta la pregunta del usuario con esa información relevante. Finalmente, el LLM genera la respuesta basándose en esa nueva información contextualizada. Esto ayuda a reducir las "alucinaciones" del modelo y a proporcionar respuestas más fiables y actualizadas.
Flujo de RAG con MongoDB
El proceso general para implementar RAG usando MongoDB Atlas Vector Search y un modelo de embeddings como el de Hugging Face se puede resumir en los siguientes pasos:
- Vectorización: Convertir tus documentos de texto en vectores numéricos (embeddings) usando un modelo de lenguaje.
- Almacenamiento: Guardar estos vectores en tu colección de MongoDB.
- Búsqueda Vectorial: Cuando un usuario hace una pregunta, se convierte la pregunta en un vector y se busca en tu base de datos el vector más similar.
- Generación de la Respuesta: Se recuperan los documentos asociados a los vectores más similares y se usan para dar contexto a un LLM (como Gemini, ChatGPT, etc.), que genera la respuesta final.
Configuración previa
Configurar la Colección en MongoDB
Para almacenar los vectores de tus documentos, debes agregar un campo de tipo Array en tu schema de Mongoose. Cada objeto en el array representará un vector.
const { Schema, model } = require("mongoose");
const DetailProjectSchema = new Schema({
description: {
type: String,
},
// Este campo guardará los vectores numéricos de los documentos.
vectorSearch: {
type: [Number], // Se recomienda un array de números para los vectores
},
});
module.exports = model("DetailProject", DetailProjectSchema);
Nota: Para mayor claridad, se recomienda que el tipo del array sea [Number], ya que los vectores son una secuencia de números.
Servicio de Vectorización (Hugging Face)
Para convertir tu texto en un vector, puedes utilizar la API de Hugging Face. El modelo sentence-transformers/all-MiniLM-L6-v2 es una excelente opción.
const api_url = "https://api-inference.huggingface.co/models/sentence-transformers/all-MiniLM-L6-v2";
const hf_token = "hf_YourTokenHere";
// Este servicio toma un texto y devuelve su representación vectorial (embedding)
const getVectorSearchService = async (text) => {
const response = await fetch(api_url, {
method: "POST",
headers: {
Authorization: `Bearer ${hf_token}`,
"Content-Type": "application/json",
},
body: JSON.stringify({ inputs: text }),
});
if (!response.ok) {
const errorText = await response.text();
throw new Error(`HuggingFace API ${response.status}: ${errorText}`);
}
return await response.json();
};
const getDetailVectorSearchServiceSimplified = async () => {
// Vectoriza la pregunta o el texto de búsqueda
const queryVector = await getVectorSearchService("modelado 3D de las herramientas del Sistema FAST Completions de Maverick y se animarán para la generación de un video 2D");
// Aquí es donde harías la búsqueda en MongoDB con el vector
const projects = await getPrjectDetailVectorAggregationSearchSimple(queryVector);
return projects
}
Configurar el Índice de Vector Search en MongoDB Atlas
Una vez que tengas tu colección, debes crear un índice de Vector Search en MongoDB Atlas para que la búsqueda por vectores sea eficiente.
- Dirígete a tu cluster de MongoDB Atlas.
- Ve a la sección Atlas Search y haz clic en Create Index.
- Selecciona el tipo de índice
Vector Searchy elige tu colección.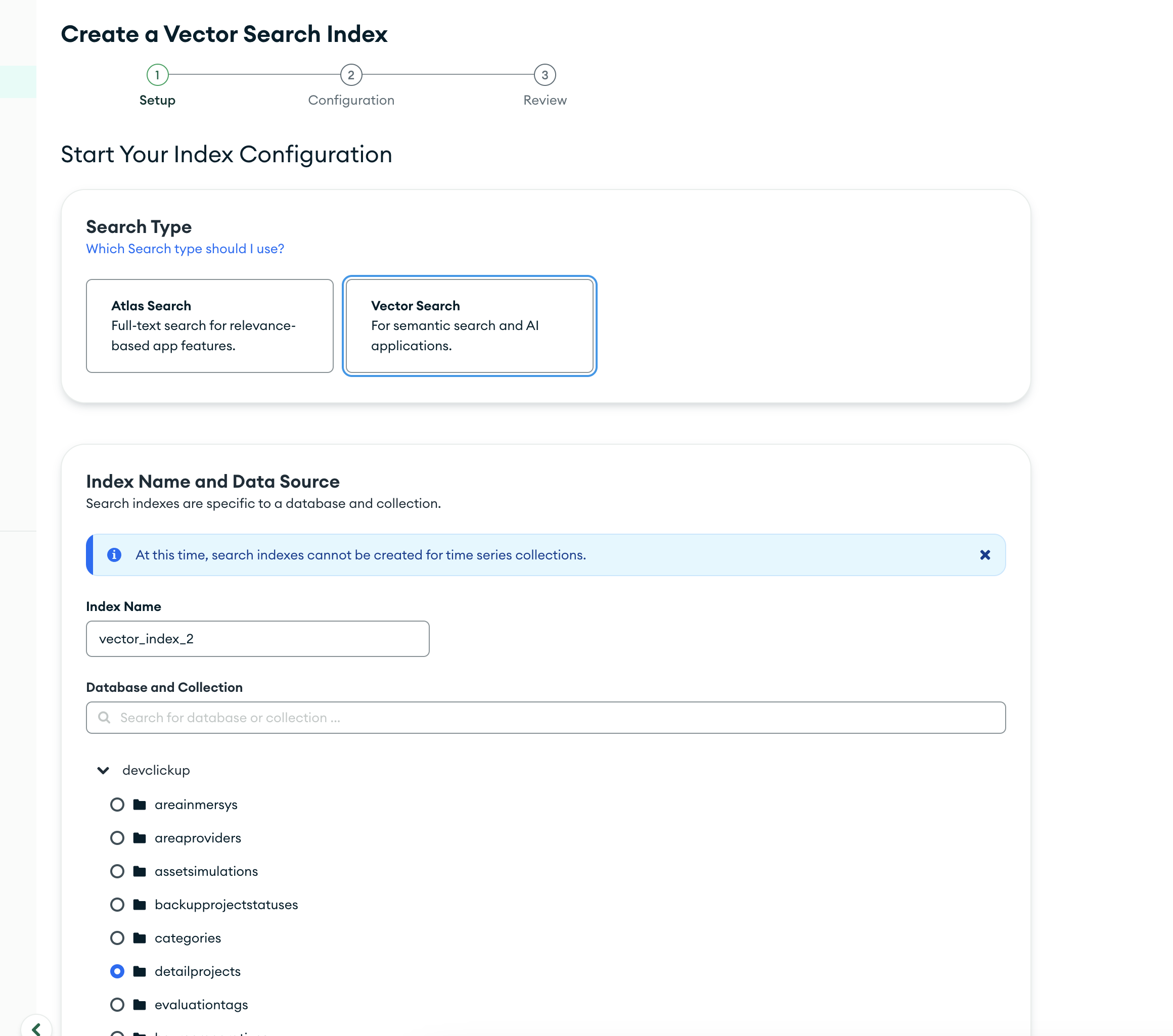
- Pega el siguiente código JSON en la configuración del índice.
{
"fields": [
{
"type": "vector",
"path": "vectorSearch",
"numDimensions": 384,
"similarity": "cosine",
}
]
}
Corrección y aclaración: El modelo all-MiniLM-L6-v2 que mencionas produce vectores con 384 dimensiones, no 2048. He ajustado el código JSON para reflejar esto. Además, he cambiado la métrica de similitud a cosine (similaridad del coseno), que es la más recomendada para embeddings de texto.
path: La ruta a tu campo que contiene los vectores.numDimensions: El número de dimensiones del vector que produce tu modelo. Paraall-MiniLM-L6-v2, es 384.similarity: La métrica matemática para medir la "distancia" o similitud entre vectores.cosinees la más común y efectiva para embeddings de texto.
Tipos de Métrica de Similitud (Similarity)
Además de la similitud del coseno (cosine), MongoDB Atlas Vector Search soporta otras métricas que pueden ser útiles dependiendo de tu caso de uso. La métrica que elijas impacta directamente en cómo se calcula la "cercanía" entre los vectores.
1. Similitud del Coseno (cosine)
Esta es la métrica más común y la que has descrito perfectamente. Mide el ángulo entre dos vectores. Es ideal para datos de texto (como los embeddings generados por modelos de lenguaje) porque se centra en la dirección de los vectores, capturando la similitud semántica sin verse afectada por la longitud del vector. Un valor de 1 indica máxima similitud, y -1 indica disimilitud.
2. Distancia Euclidiana (euclidean)
También conocida como la "distancia en línea recta", la distancia euclidiana es la métrica estándar que aprendemos en geometría. Mide la distancia geométrica entre los puntos finales de dos vectores. En este caso, un valor de 0 indica que los vectores son idénticos (máxima similitud), mientras que un valor más grande indica mayor disimilitud. La distancia euclidiana es más sensible a la magnitud (longitud) del vector, por lo que es mejor para datos donde la longitud es tan importante como la dirección, como en la búsqueda de imágenes.
3. Producto Punto (dotProduct)
El producto punto mide tanto la orientación como la magnitud de los vectores. A diferencia de la similitud del coseno, no normaliza los vectores, lo que significa que los vectores más largos tienden a tener un producto punto más alto. Un valor más alto indica mayor similitud.
- Si los vectores apuntan en la misma dirección y son largos, el producto punto será muy grande.
- Si son cortos, incluso si apuntan en la misma dirección, el producto punto será menor.
Aunque se utiliza en algunas aplicaciones, es menos común para la búsqueda de texto que la similitud del coseno, a menos que la magnitud del vector sea una característica importante para la búsqueda. Si optas por esta métrica, debes tener en cuenta que los embeddings de texto generados por muchos modelos no siempre tienen una longitud significativa para la búsqueda semántica.
Para más detalles, puedes consultar la documentación oficial de MongoDB sobre métricas de similitud.
Crear Embeddings
hay que recodar que para un embebing necesita un texto en este caso la descripción de los proyectos y se agrego
una buena practica es crear un servicio que genere los embeddings y los guarde en la base de datos y tener una collection de embeddings
const projects = await getPrjectDetailVectorSearchSimple();
const projectsIDS = projects.map(project => project._id);
await Promise.all(
projects.map(async project => {
const vectorSearch = await getVectorSearchService(project.description);
await updatePrjectDetailVectorSearch(project._id, vectorSearch);
})
);
return await getPrjectDetailVectorSearchSimple({
_id: { $in: projectsIDS }
});
const updatePrjectDetailVectorSearch = async (id, vectorSearch) => {
return await DetailProject.findByIdAndUpdate(
id,
{ $set: { vectorSearch: vectorSearch } },
{ new: true }
);
}
Codico de busqueda (ejemplo)
Ejemplo de agregación que usa $vectorSearch:
y solo buscare en la collection de embeddings
const getPrjectDetailVectorAggregationSearchSimple = async (embedding) => {
return await DetailProject.aggregate([
{
$vectorSearch: {
queryVector: embedding,
path: "vectorSearch",
numCandidates: 100,
limit: 20,
index: "vector_index_1"
}
}
])
}
Perfecto — amplié y embellecí la sección Ejemplo de tu documentación RAG con MongoDB Atlas Vector Search. Añadí un flujo end-to-end (preprocesamiento, embeddings, almacenamiento, búsqueda, re-ranking y generación), ejemplos de código en Node.js (Mongoose + Express), buenas prácticas, tuning y consideraciones de seguridad y coste. Puedes copiar y pegar esta sección directamente dentro de tu documento.
Ejemplo: implementación end-to-end de RAG con MongoDB Atlas Vector Search
Preparar los documentos (chunking + metadata)
Para mejorar la calidad de la recuperación, divide documentos largos en fragmentos (chunks) y añade metadatos (source, chunkIndex, length).
// utils/chunkText.js
function chunkText(text, maxTokens = 200, overlap = 50) {
// Implementación simple por caracteres/palabras.
const words = text.split(/\s+/);
const chunks = [];
let i = 0;
while (i < words.length) {
const end = Math.min(words.length, i + maxTokens);
const chunkWords = words.slice(Math.max(0, i - overlap), end);
chunks.push(chunkWords.join(" "));
i = end;
}
return chunks;
}
module.exports = { chunkText };
Estructura recomendada para almacenar en MongoDB (cada chunk como documento con vector):
{
_id,
projectId,
source: "mi-documento.pdf",
chunkIndex: 0,
text: "Contenido del chunk ...",
metadata: { title: "...", section: "...", lang: "es" },
vectorSearch: [ /* 384 números */ ],
createdAt: Date
}
Modelo Mongoose
const { Schema, model } = require("mongoose");
const DetailProjectSchema = new Schema({
projectId: String,
source: String,
chunkIndex: Number,
text: String,
metadata: { type: Object, default: {} },
vectorSearch: { type: [Number], default: [] },
createdAt: { type: Date, default: Date.now },
});
module.exports = model("DetailProject", DetailProjectSchema);
Servicio de embeddings (Hugging Face y alternativa OpenAI)
Hugging Face (ejemplo asíncrono)
// services/embeddings/hf.js
const fetch = require('node-fetch');
const HF_API = 'https://api-inference.huggingface.co/models/sentence-transformers/all-MiniLM-L6-v2';
const HF_TOKEN = process.env.HF_TOKEN;
async function getEmbeddingHF(text) {
const res = await fetch(HF_API, {
method: 'POST',
headers: { Authorization: `Bearer ${HF_TOKEN}`, 'Content-Type': 'application/json' },
body: JSON.stringify({ inputs: text })
});
if (!res.ok) throw new Error(`HF ${res.status}: ${await res.text()}`);
const emb = await res.json(); // formato: array de floats
// Ajusta si HF devuelve wrapper u otro formato
return emb;
}
module.exports = { getEmbeddingHF };
OpenAI (alternativa)
// services/embeddings/openai.js
const OpenAI = require("openai");
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
async function getEmbeddingOpenAI(text) {
const r = await client.embeddings.create({
model: "text-embedding-3-small", // ejemplo
input: text
});
return r.data[0].embedding;
}
Guardar embeddings
const DetailProject = require('../models/DetailProject');
const { getEmbeddingHF } = require('../services/embeddings/hf');
async function indexAllProjects() {
const docs = await DetailProject.find({ vectorSearch: { $eq: [] } });
for (const d of docs) {
const vector = await getEmbeddingHF(d.text);
await DetailProject.findByIdAndUpdate(d._id, { $set: { vectorSearch: vector }});
}
}
Mejor práctica: procesar en batches y con concurrencia controlada (p. ej. p-limit) para evitar rate limits.
Índice Vector Search en Atlas
Ejemplo JSON para el índice (ya lo tienes). Repetido aquí por completitud:
{
"fields": [
{
"type": "vector",
"path": "vectorSearch",
"numDimensions": 384,
"similarity": "cosine"
}
]
}
Nota: asegura
numDimensionscoincida con el modelo de embeddings que uses.
Consulta vectorial (agregación con $vectorSearch)
Ejemplo que devuelve score y top K:
const getPrjectDetailVectorAggregationSearchSimple = async (embedding, { index = "vector_index_1", limit = 5, numCandidates = 100 } = {}) => {
return await DetailProject.aggregate([
{
$vectorSearch: {
queryVector: embedding,
path: "vectorSearch",
index,
numCandidates,
limit,
// Puedes proyectar score
score: { $meta: "searchScore" }
}
},
{
$project: {
text: 1,
source: 1,
chunkIndex: 1,
metadata: 1,
score: { $meta: "searchScore" }
}
}
]);
};
Endpoint de búsqueda + ensamblado del prompt (Express)
// routes/search.js
const express = require('express');
const router = express.Router();
const { getEmbeddingHF } = require('../services/embeddings/hf');
const { getPrjectDetailVectorAggregationSearchSimple } = require('../services/mongoSearch');
const { callLLM } = require('../services/llm/openai'); // función que llama al LLM
router.post('/search', async (req, res) => {
try {
const { query } = req.body;
const qEmb = await getEmbeddingHF(query);
const docs = await getPrjectDetailVectorAggregationSearchSimple(qEmb, { limit: 6 });
if (!docs || docs.length === 0) {
return res.json({ answer: "No se encontraron documentos relevantes.", docs: [] });
}
// Construir prompt: incluye top-N fragmentos con metadata
const contextText = docs.map((d, i) => `Documento ${i+1} (fuente: ${d.source}, chunk: ${d.chunkIndex}):\n${d.text}`).join("\n\n---\n\n");
const prompt = `
Eres un asistente que responde en español. Usa SOLO la información provista en el contexto para responder.
Contexto:
${contextText}
Pregunta: ${query}
Respuesta (breve y concisa):
`;
// Llamada al LLM
const answer = await callLLM(prompt);
return res.json({ answer, docs });
} catch (err) {
console.error(err);
res.status(500).json({ error: err.message });
}
});
module.exports = router;
Tutorial de Video y Referencias
El video que has proporcionado es un excelente recurso. Para completar la sección de referencias, también puedes incluir los enlaces de la documentación oficial que ya tienes, que son muy útiles.